










April 24, 2018
Bigger is better . . . isn’t it?
When it comes to assessment, this seems to be a common misconception: Some educators mistakenly believe that longer tests are always better measures of student learning.
However, that’s just not true. There has been a lot of innovation over the last 170 years of American assessment. Today, it’s absolutely possible to have very short assessments that provide educators with highly reliable, valid, and meaningful data about their students.
Let’s explore the test designs, technology, and approaches that make shorter tests possible—and help you figure out if a shorter test is a better option for you and your students.
How does item format affect testing time, reliability, and validity?
An assessment can feature one or more item formats, such as constructed-response items (e.g., essay questions), performance tasks (e.g., asking a student to draw a graph or conduct an experiment), and selected-response items (e.g., true/false and multiple-choice questions).

It’s important to note that there is no universal “best” item format. A well-designed assessment may use any of these formats, or a mix of formats, and be reliable and valid. Which format to use depends on what you’re trying to assess. If you want to understand a student’s opinions or thinking process, constructed-response items and performance tasks may be good options. For measuring a wide range of content—such as mastery of state standards—in a single session, selected-response items are often a better choice.
That said, there are some key differences between item formats when it comes to the time needed to administer and score an assessment. Constructed-response items and performance tasks usually take more time to complete than selected-response questions. Because these first two formats often must be graded by hand, they also tend to take longer to score than selected-response items, which can often be instantaneously and accurately scored by computer. This is important because the faster teachers can get results from assessments, the faster they can act on that data and get students the help they need.
Even within an item format, there is still a lot of variability. Take fill-in-the-blank or cloze items, for example. If you place the answer blank near the beginning of the sentence (or “stem”), students may need to reread the question multiple times to understand what it’s asking. The more students have to reread, the longer the test will take. Placing the blank near the end of the sentence can help minimize the amount of rereading required and thus speed up the test. This means two multiple-choice questions could have the same number of items, assess almost identical content, and have very similar reliability and validity, but one could take longer to complete!
Clearly, longer tests are not inherently better.

When writing your own test or purchasing one from an assessment provider, be sure to ask these questions about item format:
- What is the best item format for the content of this assessment?
- Does this item format match any time limitations I may have for test administration?
- How will this item format be scored and how long will it take to get results?
- Are the items written in a way that minimizes rereading and overall testing time?
How does item quantity affect testing time, reliability, and validity?
Another important element to consider is the number of items included in the assessment. The quantity of items will have a notable impact on length, reliability, and validity.
In general, the more items an assessment has, the longer the assessment will take. It’s pretty clear that a test with ten multiple-choice questions will usually take longer than one with only two multiple-choice questions. However, this rule isn’t universal—as discussed above, different item formats have different time requirements, so two essay questions may take much longer than ten multiple-choice questions.
Assuming all questions on an assessment have the same format, there is a fairly linear relationship between quantity and length. Doubling the number of questions on a test will also double the test’s length (or could lengthen the test further if student fatigue or boredom slow response times). Plotted on a graph, the relationship will generally be a straight line.
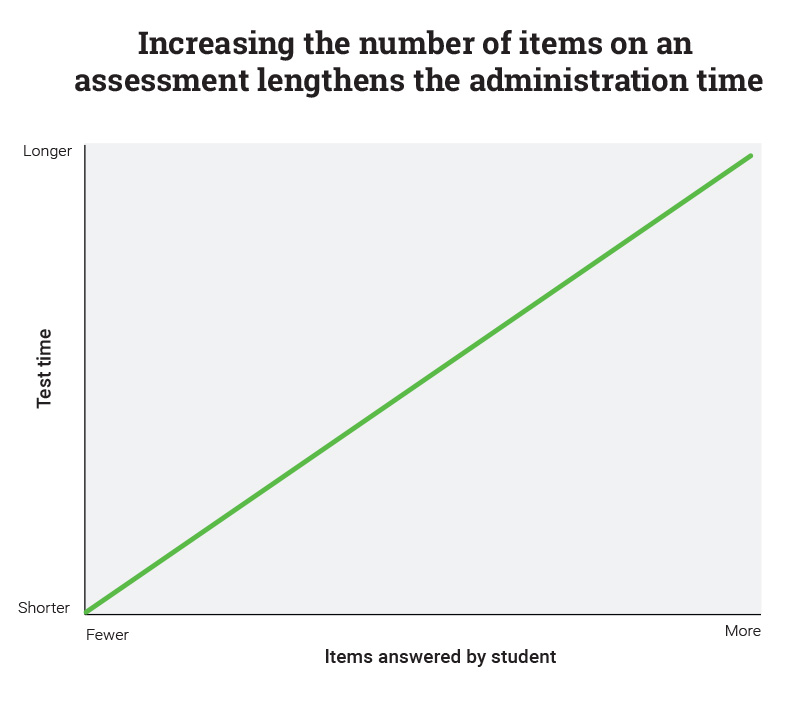
Longer assessments also tend to be more reliable—but the relationship between item quantity and length is very different than the relationship between item quantity and reliability.
If you have a short test, adding one or two additional items could markedly increase the reliability. However, if you have a long test, adding a few questions may have only a tiny effect on reliability. It’s a classic case of diminishing returns and, at a certain point, it’s just not worth it to keep adding items. In fact, for a very long test, adding many more items may barely improve reliability—and might even decrease reliability if students get tired or bored and start to guess answers.
On a graph, the relationship between quantity and reliability is usually a curve that starts out steep and then flattens as more and more items are added. (The exact shape of this curve will vary depending on the assessment.) Since reliability is a key component of validity—assessments must be reliable in order to be valid—validity often follows a similar curve in relation to test length.
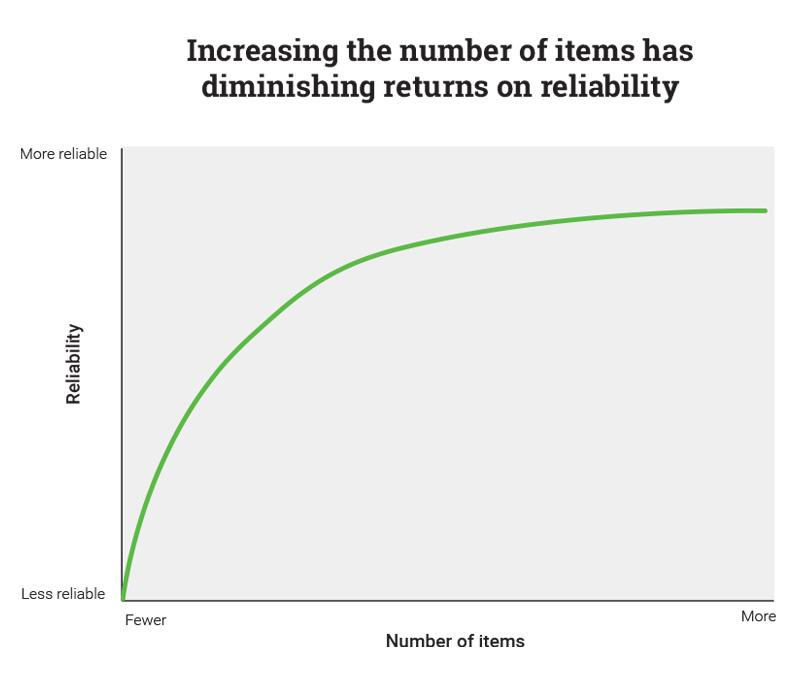
Do tests with more items take more time—are longer tests longer? Definitely, yes. Are longer tests more reliable? Generally, yes. Are they better? That’s a different question entirely.
Let’s first look at something called standard error of measurement (SEM), which is closely related to reliability: As reliability increases, SEM decreases. In simple terms, SEM describes the size of the range in which a student’s “true score” is likely to fall. Since no test can get a “perfect” measure of a student’s ability (their “true score”), all tests have an SEM.
If the SEM is 1 and a student’s score is 5, their “true score” is likely to be 4 (5 minus SEM), 5, or 6 (5 plus SEM). It’s important to consider a test’s score range when contemplating SEM: If the score range is only 30 points, you should worry if the SEM is 10 points—but if the range is 300, an SEM of 10 could be very good! For this reason, you cannot compare SEMs between two different tests (a SEM of 10 may be worse than an SEM of 100 depending on the ranges).
Try this thought exercise. Say you have two tests that use the same score scale from 0 to 100. One is 15 minutes long with an SEM of 4, meaning a child who scores 75 is likely to have a “true score” as low as 71 or as high as 79. The other test is 60 minutes long and has an SEM of 2. In this case, a child who scores 75 is likely to have a “true score” as low as 73 or as high as 77. Which test is better?
Well, that depends on what you’re going to do with the assessment data. If this is a summative assessment that is administered only once and determines if a student advances to the next grade, you may decide the longer test with the smaller SEM is the best option. Accuracy would be paramount and you’d lose relatively little instructional time.
On the other hand, if you’re using the assessment to inform instructional decisions and testing students every month, you may choose the shorter assessment with the larger SEM. Perhaps you’re grouping all students with scores between 60 and 80 in the same instructional group. In this case, a score of 71, 75, or 79 won’t change the instruction a child receives and you’ll get 45 more minutes of instructional time every month. Here, efficiency takes priority and shorter is far better.
So which is better? Only you can answer. When evaluating length and reliability, you should:
- Ensure all assessments meet your reliability standards—an unreliable test is no good, no matter how short or long it is.
- Get the greatest reliability per minute—if two tests have similar reliability and validity, the shorter one is often the better choice.
- Take a holistic look at your return on investment—if you’re sacrificing a lot of extra time for a little extra reliability, think about how you’ll use the results and whether the small increase in reliability is meaningful for your purposes.
- Watch out for tests that are longer than your students’ attention spans—fatigue, boredom, and stress can all result in artificially low scores that don’t reflect students’ real skill levels.
How does computer-adaptive testing (CAT) affect testing time, reliability, and validity?
Remember how we said that longer tests are generally more reliable? There’s one big exception to that rule: computer-adaptive testing, also known as computerized adaptive testing or CAT.
With CAT, each student’s testing experience is unique. When a student answers a question correctly, the assessment automatically selects a more difficult item to be the next question. When a student answers a question incorrectly, the opposite occurs and the next item is less difficult than the current one. Since a well-designed CAT assessment has thousands of questions in its item bank, even if students have similar skill levels, they’ll likely see different questions—and the same student could even test and re-test without items being repeated.

Tailoring item difficulty according to student ability has several notable benefits. Since students do not see overly challenging items, they are less likely to be stressed, anxious, or intimidated. Similarly, since they do not see overly easy items, they are less likely to become bored or careless. When these negative emotions and distractions are reduced, scores tend to be more reliable and valid.
Perhaps more important, CAT requires fewer items to gauge a student’s skill level since it essentially “skips” the too-easy and too-hard questions that would need to be included on a traditional test. Think of it this way: If you have no idea what a student’s math level is, a traditional or fixed-form test (where all students see the same questions) needs to include everything from basic addition all the way up to advanced algebra or even calculus. That’s a very long test—and if it only has a few questions for each skill, it may not be very precise!
Meanwhile with CAT, if a student answers two or three algebra questions correctly—something like finding x if (22x – 57) • (144 + 289) = -5,629—then the test will not ask basic addition, subtraction, and multiplication questions. Instead, it will present more and more difficult questions until the student has an incorrect answer. This means a computer-adaptive test needs fewer items overall to pinpoint the student’s ability level.
In addition, CAT can provide more precise measures for low-achieving and high-achieving students than traditional tests. Consider the low-achieving student who cannot answer any questions on a 50-item fixed-form algebra test; we know his math skill level is below algebra, but how far below? The traditional test provides little insight. In contrast, after a student provides an incorrect answer on a computer-adaptive test, the test will continue to adapt down until it finds the student’s actual level, even if it’s far below the initial starting point. CAT essentially mimics what an expert teacher would do if she could personally question each student and thus can provide a more precise measure of student skill.
“The basic notion of an adaptive test is to mimic automatically what a wise examiner would do.” — Howard Wainer
As a result of all these factors, a well-designed CAT can be two or more times as efficient as traditional tests. In other words, if a traditional test has 50 items, a CAT assessment may need only 25 items to reach the same reliability; or, if both tests have the same number of items, the CAT one is likely to be more reliable. Along with improved reliability, CAT assessments also tend to have improved validity over traditional assessments. Shorter tests can be more reliable and more valid!
In fact, hundreds of studies have shown that even very short CAT assessments (including ones that take some students as little as 11 minutes to finish) can predict performance on much longer fixed-form assessments. For example, watch the short 1.5-minute clip below from the on-demand webinar Predicting Performance on High-Stakes Assessments, in which a researcher discusses why one popular CAT assessment is a good predictor of performance on year-end summative state tests.
The benefits of CAT are so great that some high-stakes assessments are moving from fixed-form to computer-adaptive. Is CAT right for you and your students? You should definitely consider CAT if:
- Your students represent a wide range of ability levels and you need to know exactly how high or how low their skill levels are—CAT means you can use one test for an accurate measure of all students’ skill levels.
- You have limited time to administer tests or need to assess students multiple times throughout the year—shorter CAT assessments could help you protect your instructional time without sacrificing reliability or validity.
- You want a reliable measure of student progress over the school year or from year to year—CAT assessments will adapt up as students’ skill levels improve, allowing you to use the same test in multiple grades for directly comparable scores.
Are you assessing in the past—or in the future?
Back in 1845, multiple-choice questions had yet to be invented, formal adaptive testing didn’t exist, digital computers were almost 100 years away, and the United States’ first mandated written assessment took one hour. Today, things have changed a lot, but many assessments still seem stuck in the past. How many “modern” assessments still take an hour or more? How many need to take that long?
Could a shorter test give you the reliability, validity, and insights you need to support student success?
Before you decide on your best assessment, there’s one more factor you need to consider—the critical element that bridges assessment and instruction. In part two of this blog, we examine why learning progressions are so essential for good assessments.
Sources
Beck, J. E., Mostow, J., & Bey, J. (2003). Can automated questions scaffold children’s reading comprehension? Pittsburgh, PA: Carnegie Mellon University Project LISTEN.
Bell, R., & Lumsden, J. (1980). Test length and validity. Applied Psychological Measurement, 4(2), 165-170.
Brame, C. J. (2013). Writing good multiple choice test questions. Vanderbilt Center for Teaching. Retrieved from https://cft.vanderbilt.edu/guides-sub-pages/writing-good-multiple-choice-test-questions/
Clay, B. (2001). Is this a trick question? A short guide to writing effective test questions. Lawrence, KS: University of Kansas Curriculum Center.
Croft, M., Guffy, G., & Vitale, D. (2015). Reviewing your options: The case for using multiple-choice test items. Iowa City, IA: ACT.
Fetzer, M., Dainis, A., Lambert, S., & Meade, A. (2011). Computer adaptive testing (CAT) in an employment context. Surrey, UK: SHL.
Galli, J. A. (2001). Measuring validity and reliability of computer adaptive online skills assessments. Washington, DC: Brainbench. Retrieved from https://www.brainbench.com/xml/bb/mybrainbench/community/whitepaper.xml?contentId=938
Leung, C. K., Chang, H. H., & Hau, K. T. (2003). Computerized adaptive testing: A comparison of three content balancing methods. The Journal of Technology, Learning, and Assessment, 2(5), 1-15.
Livingston, S. A. (2009). Constructed-response test questions: Why we use them; how we score them. ETS R&D Connections, 11, 1-8.
Mattimore, P. (2009, February 5). Why our children need national multiple choice tests. Retrieved from http://www.opednews.com/articles/Why-Our-Children-Need-Nati-by-Patrick-Mattimore-090205-402.html
Monaghan, W. (2006). The facts about subscores (ETS R&D Connections No. 4). Princeton, NJ: Educational Testing Services. Retrieved from http://www.ets.org/Media/Research/pdf/RD_Connections4.pdf
Nicol, D. (2007). E-assessment by design: Using multiple-choice tests to good effect. Journal of Further and Higher Education, 31(1), 53–64.
Phipps, S. D., & Brackbill, M. L. (2009). Relationship between assessment item format and item performance characteristics. American Journal of Pharmaceutical Education, 73(8), 1-6.
Popham, W. J. (2008). Classroom assessment: What teachers need to know (5th ed.). Boston: Allyn and Bacon.
Popham, W. J. (2009). All about assessment / unraveling reliability. Educational Leadership, 66(5), 77-78.
Renaissance Learning. (2015). Star Math technical manual. Wisconsin Rapids, WI: Author.
Renaissance Learning. (2015). Star Reading technical manual. Wisconsin Rapids, WI: Author.
Shapiro, E. S., & Gebhardt, S. N. (2012). Comparing computer-adaptive and curriculum-based measurement methods of assessment. School Psychology Review, 41(3), 295-305.
Stecher, B. M., Rahn, M., Ruby, A., Alt, M., Robyn, A., & Ward, B. (1997). Using alternative
assessments in vocational education. Santa Monica, CA: RAND Corporation.
Stiggins, R. J. (2005). Student-involved classroom assessment for learning (4th ed.). Upper Saddle
River, NJ: Pearson/Merrill Prentice Hall.
Wainer, H. (2000). CATs: Whither and whence. Princeton, NJ: Educational Testing Services. Retrieved from https://doi.org/10.1002/j.2333-8504.2000.tb01836.x
Weiss, D. J. (2004). Computerized adaptive testing for effective and efficient measurement in counseling and education. Measurement and Evaluation in Counseling and Development, 37, 70-84. Retrieved from http://www.psych.umn.edu/psylabs/catcentral/pdf%20files/we04070.pdf
Wells, C. S., & Wollack, J. A. (2003). An instructor’s guide to understanding test reliability. Madison, WI: University of Wisconsin Testing & Evaluation Services.
Young, J. W., So, Y., & Ockey, G. J. (2013). Guidelines for best test development practices to ensure validity and fairness for international English language proficiency assessments. Princeton, NJ: Educational Testing Service (ETS).